关键要点
让测试人员参与基于机器学习(ML)的项目并不常见,但如果这样做,已被证明是非常有益的。
如果测试人员了解 ML 系统的不同组件和结构,他们可以更好地对其进行测试。
与开发人员合作探索/执行新的测试想法有助于确保基于 ML 的系统的质量。
深厚的产品知识、对细节的关注和开箱即用的测试理念可以在测试 ML 系统中发挥重要作用。
测试人员可以在测试 ML 模型的训练和部署方面增加价值。
介绍
测试被认为是软件开发生命周期(SDLC)中的一个重要方面,因此测试人员参与其中以确保应用程序的质量。这适用于传统的软件系统,包括 Web 应用程序、移动应用程序、Web 服务等。
但是你有没有想过基于机器学习的系统?在这些情况下,测试退居次要地位。即使进行了一些测试,也主要是由开发人员自己完成的。在这些领域,测试人员的角色没有被清楚地描绘出来。
测试人员通常很难理解基于 ML 的系统,并探索他们可以在此类项目中做出哪些贡献。因此,在本文中,我将分享我作为测试人员确保基于 ML 的系统质量的旅程。我将重点介绍我的挑战、学习和我的成功故事。
我从测试传统系统过渡到基于 ML 的系统
像大多数测试人员一样,我一直参与测试涉及Web应用程序,本机应用程序,后端,微服务等的传统系统。在这样的系统中,输入由人类(主要是开发人员)进行输入并编写逻辑以产生确定性输出。作为测试人员,我们的重点是根据指定/隐含的要求验证预期输出。
有趣的是,几年前我有机会测试基于 ML 的推荐系统。它与传统系统完全不同,所以我既兴奋又焦虑。
在 ML 系统中,大量带有模式的数据作为输入给出。它被馈送到一个模型,该模型学习逻辑来发现这些模式并预测未来事件。
为了确保质量,测试学习的逻辑非常重要。所以我问自己,我该如何测试这个学习过程和模型学习的逻辑?甚至有可能测试这个逻辑吗?模型完全是黑匣子吗?
脑子里有很多这样的问题,我很好奇去探索和学习。我已经准备好坐过山车了:)
我的第一步和学习
在我兴奋和好奇心中快速贡献,我做了我们大多数人都会做的事情 - 谷歌测试想法!我提到的大多数资源都指向模型评估指标,如精度、召回率、混淆矩阵等。对我来说,它们就像行话。老实说,我不明白他们。但是我把我半生不熟的知识带回给我的开发人员,他们告诉我他们已经在考虑这些指标了。
我意识到开发人员精通他们的领域。为了作为测试人员产生影响,我需要引入他们错过的观点。
作为测试人员,我们有幸拥有提出正确问题、了解大局、跳出框框思考、应用更深入的产品知识、挑战现状等的高超技能。如果将这些技能应用于测试 ML 系统,则可以防止很多问题。
我还意识到我试图测试一些东西,甚至不了解系统的工作原理和构建块是什么。但是,为了更好地测试任何系统,这应该是第一步。
我与我的开发人员讨论了这种方法,以便合作深入了解系统,并在每个阶段应用我的测试技能。
开发人员最初对是否有测试人员持怀疑态度,但在听到这个计划后感到兴奋,并期待着我能提供的价值。
了解 ML 系统的基础知识
我和我的团队一起了解到,在机器学习中,收集、过滤并馈送到模型的大量具有特定模式的数据。该模型识别这些模式并预测未来事件的概率。
例如,我们的项目是为我们的用户提供文章推荐。因此,收集了大量的数据,如平台上的文章交互、用户特征和用户行为,并将其提供给模型。然后,该模型学习了数据中的模式并形成了规则,以预测用户与文章交互的未来可能性。
该过程分为两个阶段:
阶段 A - 模型学习,其中模型从数据中学习和识别模式并提出逻辑。
阶段 B - 部署模型,向模型提供新的未见过的数据。该模型将学习的逻辑应用于新数据并进行预测。
阶段 A - 机器学习系统的学习过程
在学习阶段,模型学习从数据中识别模式,并提出逻辑来做出未来的预测。
有两种类型的学习过程:监督学习和无监督学习。我们的项目有监督学习,其中所需的输出样本在训练数据本身中可用。
详细的学习过程如下:
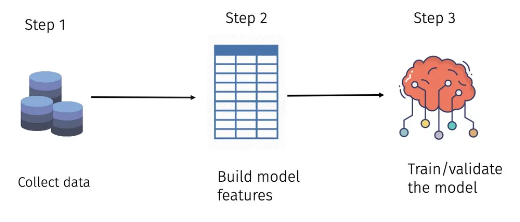
第 1 步 - 数据收集:ML 系统的训练在很大程度上取决于输入数据。根据经验:“数据越多,训练越好”。但通常有一种不关注数据质量的倾向。
我确实会说,“数据质量越高,训练越好”。
因此,作为测试人员,我们可以帮助开发人员检查/修复所有质量维度,例如:
缺失值
不正确的值/数据类型
不一致
重复
安全问题
业务规则
偏见
异常值数据
等等
让我们举一个简单的例子。在我们的数据中,名为“article_age”的列在某些情况下具有负值。此列反映了文章创建的时间,当然这不应该是负面的。我们发现这些负值是由于时区转换中的错误造成的,因此我们对其进行了修复以更正数据。
应将所有此类检查添加并集成到管道中,以验证数据质量。
第 2 步 - 构建模型特征:收集和细化数据后,下一步是设计模型特征。形成一个包含所有数据的表以馈送到模型。每列称为模型特征,但一列除外,该列是目标值。所有列都有数值。
例如,对于我们的文章推荐系统,有与用户细节相关的功能,如年龄、性别、用户订阅持续时间;文章特定的功能,例如自发布以来的时间、文章的总浏览量/展示次数、文章的总点击量;有关用户与文章交互的功能,例如用户查看或单击文章的次数等,等等。
反映用户是否与文章交互的目标值。
若要正确训练模型,选择正确的特征非常重要。
作为一名测试人员,我帮助审查了所有功能,标准化了应用于它们的规则,并应用产品知识来查找错误/增强功能。一些例子:
在计算“文章浏览量”功能时,唯一用户浏览量被计算在内,这意味着如果某个用户多次看到一篇文章,那么它只被计为一次浏览。因此,我确保必须将相同的唯一计数规则应用于其他功能,例如“点击文章”、“文章互动”等。
有关于用户工作行业的可用数据,这不是我们模型中的特征。我挑战了现状并添加了此功能,因为它对模型学习很有价值(来自同一行业的用户可能倾向于阅读相同的文章)。
我扮演的一个重要角色是记录特征及其描述、规则等。
步骤 3 - 模型的训练和验证:收集数据并确定特征后,是时候将此数据输入模型并进行训练了。
这是模型提出规则的地方,用于预测未来目标值何时将向其提供新数据。
并非所有数据都应用于训练模型。但数据应拆分为训练数据和测试数据。模型应使用训练数据进行训练,并且必须使用不同的模型评估指标(如精度、召回率、rpAUC 等)使用测试数据验证模型学习的逻辑。
也可以通过分析每个模型特征的重要性(例如使用SHAP值)来进行一些评估。测试人员可以帮助评估特征重要性图并提出正确的问题。
例如,在我们推荐文章的模型中,我意识到模型预测认为文章年龄的特征是最不重要的。我很惊讶并提出了这个问题,因为如果模型了解到年龄是数据中最不重要的东西,那么它可以推荐具有相同概率的新旧文章。对于与时间相关的文章,这可能会有问题,因为新发表的文章比旧发表的文章重要得多。开发人员发现在训练过程中发生了一些错误,导致了这个错误,因此重新训练了模型。
阶段 B - 部署(新版本)模型
现在模型是用过去的数据训练的,下一步是提供新的看不见的数据来预测未来事件的概率,这基本上意味着将新模型部署到生产环境中。
若要测试新模型的部署,请务必了解其在生产中的设置。
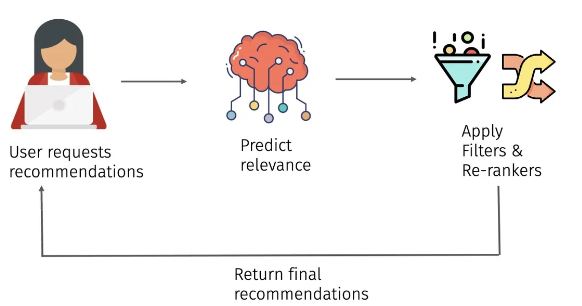
例如,在我们的文章推荐器案例中,当用户请求推荐时,会发出 API 请求以获取模型的预测。除了模型的结果之外,还应用了一些过滤器和重新排名器。筛选器是指删除模型预测的某些项的业务规则。重新排名器是业务规则,用于打乱模型预测的一些项目。
在上面的设置中,每当我们计划部署新训练的模型来替换现有模型时,都会在替换之前执行某些测试以确认值得替换。
我们对用户在旧版本和新版本中看到的最终结果进行了比较分析。我们从两个版本的输出中收集了前 X 个项目,并比较了它们的不同指标,例如更改/相同项目的数量、平均文章年龄的影响、对项目多样性的影响等。
仔细分析这些结果有助于我们决定是否部署新模型。例如,一旦我们注意到在新模型中,向用户显示的前 10 篇文章的平均年龄大幅下降,这对我们来说是一个阻碍部署的障碍,因为我们不想在新文章可用时向用户显示旧内容。
执行此类测试总是让我们对新模型的质量充满信心。
此外,每当过滤器或重新排名的规则发生变化时,我都会测试相关更改,有时甚至会发现关键错误。例如,我们想添加一个过滤器,该过滤器应该只保留两篇具有相同作者的文章,并从该作者中删除其余文章。但我注意到过滤器允许来自同一篇文章的三篇文章,而不是两篇文章。开发人员意识到由于请求不明确而引入了此错误并修复了它。这个小修复确实在很大程度上改变了我们用户的结果。
因此,每当在设置中进行任何更改时,在部署之前进行测试绝对至关重要。
话虽如此,最终我们的用户是我们最终的测试人员。因此,我们不只是发布新模型,而是始终进行A / B测试,将用户组分成2组。组 A 中的用户收到旧版本,B 组中的用户收到新版本。在让测试运行一段时间(几周)后,我们从两组收集了数据,并根据点击率、滚动距离、与项目的参与度等指标分析了新模型/重新排名器/过滤器是否真的表现得更好。根据结果,我们决定新版本是否值得向所有人推出。然后收集这些数据并用于重新训练新模型。
我从旅途中学到的东西
一开始,我对自己在ML系统项目中的角色持怀疑态度。
但回顾我的旅程,我了解到影响测试人员可以做出多大的影响。我已经了解到如果不进行测试,可能会发生什么错误。我了解了测试人员如何与开发人员密切合作,甚至可以使用 ML 系统发现问题。
简而言之,我了解到现在是改变“测试人员无法为 ML 系统做出贡献”的看法的时候了。
感谢Rahul Verma,Prabhu和Ben Linders激励我写这篇文章,并彻底审查它,以帮助它达到目前的形状。
作者简介: 希瓦尼·加巴
Shivani Gaba是德国New Work SE的团队主管工程。她是一位经验丰富的演讲者,曾在各种国际会议上发表演讲。她认为,知识共享可以增强所有参与方并增强他们的信心。那是2013年的夏天,加巴和“测试”第一次见面,从此成为最好的朋友。ML在测试领域拥有丰富的经验,在软件测试的各个层面都有实践经验,包括UI(前端),API和后端,功能,非功能,机器学习(ML)移动测试,ML仍然是她一直以来的最爱。作为一名经过认证的Scrum主管,以敏捷的方式工作始终是她的方法。她相信传播她学到的任何“新花哨的东西”的发现的想法。她曾与多个国际团队合作,并提出了整个团队为质量做出贡献的想法。她总是通过电子邮件、LinkedIn、Xing、推特或啤酒桌进行交谈:)