强大的机器学习模型正被用于帮助人们解决棘手的问题,例如识别医学图像中的疾病或检测自动驾驶汽车的道路障碍物。但是机器学习模型可能会犯错误,因此在高风险环境中,人类知道何时信任模型的预测至关重要。
不确定性量化是提高模型可靠性的一种工具;该模型生成一个分数以及表示预测正确的置信度的预测。虽然不确定性量化可能很有用,但现有方法通常需要重新训练整个模型才能赋予其这种能力。训练涉及向模型展示数百万个示例,以便它可以学习任务。然后,重新训练需要数百万个新的数据输入,这可能既昂贵又难以获得,并且还会使用大量的计算资源。
麻省理工学院和麻省理工学院-IBM沃森人工智能实验室的研究人员现在已经开发出一种技术,使模型能够执行更有效的不确定性量化,同时使用比其他方法少得多的计算资源,并且没有额外的数据。他们的技术不需要用户重新训练或修改模型,对于许多应用程序来说足够灵活。
该技术涉及创建一个更简单的伴随模型,以帮助原始机器学习模型估计不确定性。这个较小的模型旨在识别不同类型的不确定性,这可以帮助研究人员深入了解预测不准确的根本原因。
“不确定性量化对于机器学习模型的开发人员和用户都至关重要。开发人员可以利用不确定性测量来帮助开发更稳健的模型,而对于用户来说,在现实世界中部署模型时,它可以增加另一层信任和可靠性。我们的工作为不确定性量化提供了一种更灵活和实用的解决方案,“电气工程和计算机科学研究生,关于该技术的论文的主要作者Maohao Shen说。
沈宇恒与前电子研究实验室(RLE)博士后、现任佛罗里达大学助理教授卜宇恒一起撰写了这篇论文;Prasanna Sattigeri,Soumya Ghosh和Subhro Das,麻省理工学院-IBM沃森人工智能实验室的研究人员;资深作者Gregory Wornell,住友工程学教授,领导信号,信息和算法实验室RLE,并且是MIT-IBM Watson AI实验室的成员。该研究将在AAAI人工智能会议上发表,该论文可在arXiv预印本服务器上获得。
量化不确定性
在不确定性量化中,机器学习模型为每个输出生成一个数字分数,以反映其对该预测准确性的置信度。通过从头开始构建新模型或重新训练现有模型来合并不确定性量化通常需要大量数据和昂贵的计算,这通常是不切实际的。更重要的是,现有方法有时会产生降低模型预测质量的意外后果。
因此,麻省理工学院和麻省理工学院-IBM沃森人工智能实验室的研究人员将注意力集中在以下问题上:给定一个预先训练的模型,他们如何使其能够执行有效的不确定性量化?
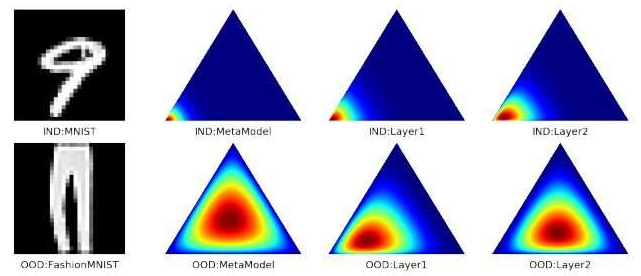
他们通过创建一个更小、更简单的模型(称为元模型)来解决这个问题,该模型附加到更大的预训练模型,并使用较大模型已经学会的特征来帮助它进行不确定性量化评估。
“元模型可以应用于任何预训练模型。最好访问模型的内部结构,因为我们可以获得有关基本模型的更多信息,但如果您只有最终输出,它也可以工作。它仍然可以预测置信度分数,“Sattigeri说。
他们设计元模型以使用包括两种不确定性的技术来产生不确定性量化输出:数据不确定性和模型不确定性。数据不确定性是由数据损坏或不准确的标签引起的,只能通过修复数据集或收集新数据来减少。在模型不确定性中,模型不确定如何解释新观察到的数据,并且可能会做出不正确的预测,很可能是因为它没有看到足够多的类似训练示例。在部署模型时,此问题是一个特别具有挑战性但常见的问题。在实际设置中,他们经常遇到与训练数据集不同的数据。
“当你在新环境中使用模型时,你的决策的可靠性是否发生了变化?你想要某种方式来相信它是否在这个新制度中起作用,或者你是否需要为这个特定的新环境收集训练数据,“Wornell说。
验证量化
一旦模型产生不确定性量化分数,用户仍然需要一些保证分数本身是准确的。研究人员通常通过创建一个较小的数据集来验证准确性,该数据集从原始训练数据中保留出来,然后在保留的数据上测试模型。然而,这种技术在测量不确定性量化方面效果不佳,因为该模型可以在仍然过于自信的同时实现良好的预测准确性,Shen说。
他们通过向验证集中的数据添加噪声来创建一种新的验证技术——这种嘈杂的数据更像是可能导致模型不确定性的分布外数据。研究人员使用这个嘈杂的数据集来评估不确定性量化。
他们通过观察元模型如何捕获各种下游任务的不同类型的不确定性来测试他们的方法,包括分布外检测和错误分类检测。他们的方法不仅优于每个下游任务中的所有基线,而且需要更少的培训时间来实现这些结果。
这种技术可以帮助研究人员使更多的机器学习模型能够有效地执行不确定性量化,最终帮助用户更好地决定何时信任预测。
展望未来,研究人员希望将他们的技术应用于更新的模型类别,例如具有与传统神经网络不同的结构的大型语言模型,Shen说。