本页面介绍如何创建 运行 Spark的Dataproc集群。
概述
在 Dataproc Metastore 服务实例与 Dataplex 湖关联后创建集群,以确保集群可以依赖 Hive Metastore 端点来访问 Dataplex 元数据。
可以通过 Hive Metastore 等标准接口访问 Dataplex 中管理的元数据,以支持 Spark 查询。查询在 Dataproc 集群上运行。
对于 Parquet 数据,将 Spark 属性设置spark.sql.hive.convertMetastoreParquet为false 以避免执行错误。更多细节。
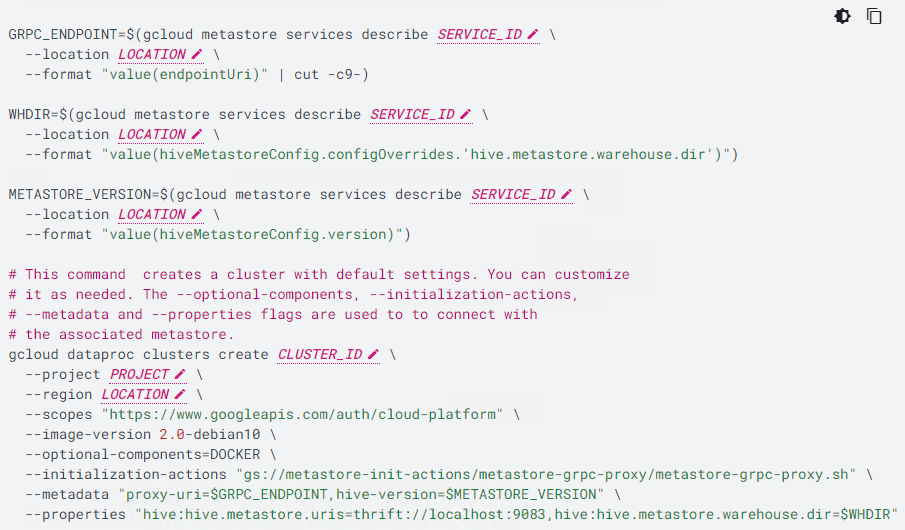
创建 Dataproc 集群
运行以下命令创建 Dataproc 集群,指定与 Dataplex 湖关联的 Dataproc Metastore 服务:
探索元数据
运行 DQL 查询以探索元数据并运行 Spark 查询以查询数据。
在你开始之前
在 Dataproc 集群的主节点上打开 SSH 会话。
在主节点命令提示符下,打开一个新的 Python REPL。
列出数据库
湖中的每个 Dataplex 区域都映射到一个 Metastore 数据库。
在元数据中创建表和分区
使用 Apache Spark 运行 DDL 查询以在 Dataplex 元数据中创建表和分区。
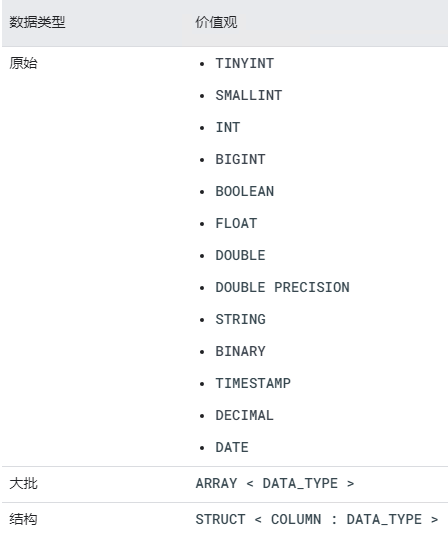
有关支持的数据类型、文件格式和行格式的更多信息,请参阅支持的值。
在你开始之前
在创建表之前,创建一个映射到包含基础数据的 Cloud Storage 存储桶的 Dataplex 资产。有关详细信息,请参阅 添加存储桶。
创建表
支持 Parquet、ORC、AVRO、CSV 和 JSON 表。
注意:如果表与配置单元分区样式兼容,'dataplex.entity.partition_style' = 'HIVE_COMPATIBLE'则作为表属性传递。
改变一张桌子
Dataplex 不允许您更改表的位置或编辑表的分区列。更改表不会自动将 userManaged设置 为true。
在 Spark SQL 中,您可以重命名表、添加列和设置表的文件格式。
重命名表
添加列
设置文件格式
放下一张桌子
从 Dataplex 的元数据 API 中删除表不会删除 Cloud Storage 中的基础数据。
添加分区
Dataplex 不允许在创建后更改分区。但是,可以删除分区。
您可以添加具有相同分区键和不同分区值的多个分区,如前面的示例所示。
删除分区
要删除分区,请运行以下命令:
查询 Iceberg 表
您可以使用 Apache Spark 查询 Iceberg 表。
注意:Iceberg 表仅在 Spark 3 (Dataproc 2.x) 中受支持。
在你开始之前
使用 Iceberg 设置 Spark SQL 会话。
创建冰山表
要创建 Iceberg 表,请运行以下命令:
探索冰山快照和历史
您可以使用 Apache Spark 获取 Iceberg 表的快照和历史记录。
在你开始之前
在 Iceberg 支持下设置 PySpark 会话。
获取 Iceberg 表的历史记录
要获取 Iceberg 表的历史记录,请运行以下命令:
获取 Iceberg 表的快照
要获取 Iceberg 表的快照,请运行以下命令:
支持的文件格式定义如下:
TEXTFILE
ORC
PARQUET
AVRO
JSONFILE
注意:Iceberg 仅支持AVRO, ORC, 和PARQUET格式。
支持的行格式定义如下:
DELIMITED [字段终止于CHAR]
SERDE SERDE_NAME [WITH SERDEPROPERTIES (PROPERTY_NAME=PROPERTY_VALUE,PROPERTY_NAME=PROPERTY_VALUE, ...)]