BBC 面向公众的网站每周为全球超过 4.98 亿成年人提供信息、教育和娱乐。由于突发新闻是如此不可预测,我们需要一个核心内容交付平台,该平台可以轻松扩展以响应流量激增,而流量激增可能是非常不可预测的。
为此,我们最近在谷歌云无服务器平台上重建了我们的日志处理基础设施。我们发现,基于Cloud Storage、Eventarc、Cloud Run和BigQuery的新系统使我们能够提供可靠和稳定的服务,而无需担心在繁忙时间进行扩展。我们还能够通过比我们以前的架构更具成本效益地运营服务来节省许可费支付者的钱。不必手动管理堆栈主要组件的规模,这解放了我们的时间,让我们可以将时间花在使用数据上,而不是创建数据上。
登录时间
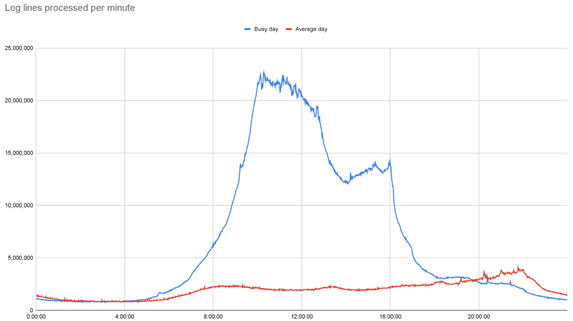
为了运营网站并确保我们的服务顺利运行,我们会持续监控流量管理器和 CDN 访问日志。我们的网站每天产生超过 3B 的日志行,并在重大新闻事件期间处理大量数据突发;在忙碌的一天,我们的系统一天支持超过 26B 的日志行。
按照最初的设计,我们将日志数据存储在 Cloud Storage 存储桶中。但每次我们需要访问该数据时,我们都必须将数 TB 的日志下载到具有大量附加存储的虚拟机 (VM),并使用“grep”工具搜索和分析它们。从头到尾,这花了我们好几个小时。在新闻繁多的日子里,时间滞后使工程团队难以完成工作。
我们需要一种更有效的方法来提供这些日志数据,因此我们设计并部署了一个新系统来处理日志并在峰值到达时更有效地对其做出反应,从而显着提高关键信息的及时性。
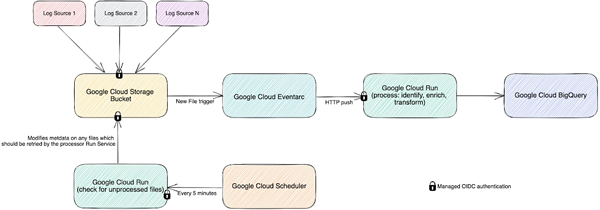
在这个新系统中,我们仍然利用 Cloud Storage 存储桶,但到达时,每个日志都会使用EventArc生成一个事件。该事件触发Cloud Run验证、转换和丰富有关日志文件的各种信息,例如文件名、前缀和类型,然后对其进行处理并将处理后的数据作为流输出到 BigQuery 中。这种事件驱动的设计使我们能够快速、频繁地处理文件——处理单个日志文件通常需要不到一秒钟的时间。我们输入系统的大多数文件都很小,不到 100 兆字节,但对于较大的文件,我们会自动将它们拆分为多个文件,Cloud Run 会非常快速地自动创建额外的并行实例,帮助系统几乎立即扩展。
运营一个提供新闻报道的全球网站的性质意味着我们会看到频繁的、不可预测的大流量高峰。我们从中吸取教训并在必要时优化我们的系统,因此我们对系统处理大量流量的能力充满信心。例如,在 9 月宣布女王去世前后,我们看到了一些巨大的流量高峰。在最大的情况下,在一分钟内,我们从运行 150 - 200 个容器实例增加到 1000 多个...... 基础设施刚刚运作。因为我们设计的日志处理系统依赖于无服务器架构的弹性,所以我们从一开始就知道它能够处理这种类型的扩展。
在 9 月宣布女王去世前后,我们看到了一些巨大的流量高峰。在最大的情况下,在一分钟内,我们从运行 150 - 200 个容器实例增加到 1000 多个...... 基础设施刚刚运作。
我们最初对选择无服务器的关注是成本。事实证明,使用 Cloud Run 比运行我们需要的 VM 数量要经济得多,因为系统能够以类似的置信度承受合理的流量峰值。
切换到 Cloud Run 还可以让我们更有效地利用时间,因为我们不再需要花时间管理和监控 VM 扩展或资源使用情况。我们特意选择了 Cloud Run,因为我们想要一个无需人工干预即可很好扩展的系统。作为数字分发团队,我们的工作不是对该系统的底层组件进行操作——我们将其留给谷歌的专业操作团队。
我们在重建系统时做出的另一个有意识的选择是使用谷歌云中内置的服务到服务身份验证。我们不是自己实施和维护身份验证机制,而是添加一些简单的配置,指示客户端为我们定义的服务帐户创建和发送 OIDC 令牌,并指示服务器端对客户端进行身份验证和授权。另一个例子是将事件推送到 Cloud Run,我们可以在其中配置 Cloud Run 授权以仅接受来自特定 EventArc 触发器的事件,因此它是完全私有的。
展望未来,新系统使我们能够更好地安全地使用我们的数据。例如,BigQuery 的每列权限允许我们向组织内的其他工程团队开放对日志的访问权限,而不必担心共享仅限于已批准用户的 PII。
我们团队的目标是让 BBC 内的所有团队能够在需要时在网络上获取他们想要的内容,使其可靠、安全,并确保它可以扩展。与前几代技术相比,Google Cloud 无服务器产品帮助我们以相对较少的努力实现了这些目标,并且需要的管理要少得多。