在上一个版本发布十年后,MariaDB Server 11.0已经发布。此版本进行了多项更改,包括新的优化器成本模型,该模型旨在更准确地预测每个查询执行计划的实际成本以及删除InnoDB更改缓冲区。
根据MariaDB基金会的说法,大多数优化器问题,例如报告有关错误查询计划的性能问题,都是由社区用户告知的。
MariaDB 11.0 的旗舰功能是新的优化器成本模型,旨在能够更准确地预测每个查询执行计划的成本。但是,不能保证在所有情况下都会更好;某些查询可能更慢。这个想法是增加MariaDB主要版本作为信号。
在MariaDB 11.0之前,MariaDB查询优化器使用“基本成本”1进行一次磁盘访问,获取密钥,根据密钥中的rowid获取行,以及其他小成本。在查找要使用的最佳索引时,这些成本是合理的,但对于表扫描、索引扫描或范围查找来说就不是那么好了。
MariaDB 11.0 将“存储引擎操作”的基本成本更改为 <> 毫秒,这意味着对于大多数查询,成本应该接近服务器在存储引擎中花费的时间 + join_cache + 排序。
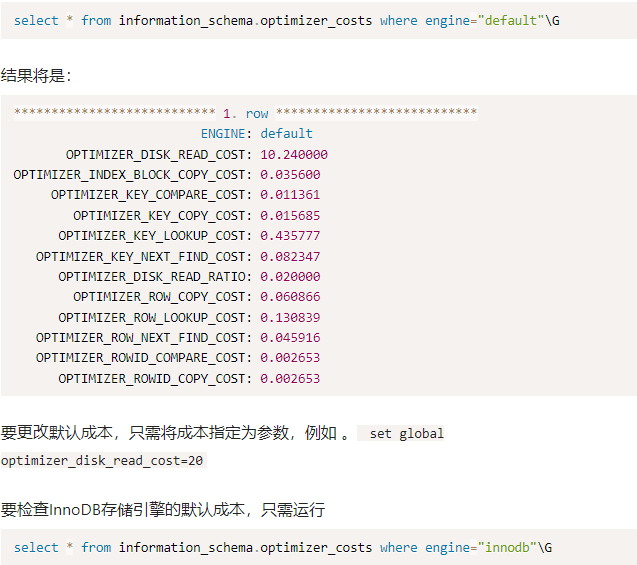
发动机成本已分成小块以提高精度。磁盘读取成本现在默认假定 SSD 磁盘的速度为 400/秒,可以通过修改 .OPTIMIZER_DISK_READ_COST
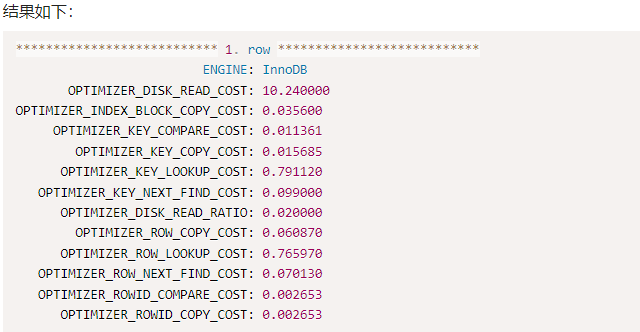
所有特定于发动机的成本都可以在 中找到。若要查看引擎的默认成本,可以使用以下查询:information_schema.optimizer_costs
让我们看一下其他 MariaDB 优化器成本变化:
对磁盘访问进行计数时,假定在查询期间缓存所有行和索引数据。
排序(filesort)的开销现在更加准确,允许优化程序更好地在索引扫描和 ORDER BY/GROUP BY 查询的文件排序之间进行选择。
新的优化器更改通常很重要,在以下情况下可能应该能够找到更好的计划:
运行包含两个以上表的查询时
具有大量相同值的索引
覆盖表的 10% 以上的范围 (WHERE key between 1 and 1000 -- Table has values 1-2000)
并非所有使用的列都已编制索引或可以编制索引时的复杂查询
混合不同存储引擎的查询,例如在同一查询中使用 InnoDB 和内存中的表
当需要使用以获得一个好的计划FORCE INDEX
如果使用分析表使计划变得更糟(或不够好)
具有大量派生表的查询(子选择)
使用可以通过索引解析的排序依据/分组依据