扩展计算性能是推进机器学习 (ML) 技术发展水平的基础。得益于互连技术和领域特定加速器 (DSA) 方面的关键创新,谷歌云 TPU v4 支持:
在扩展 ML 系统性能方面比 TPU v3 有了近 10 倍的飞跃
与当代 ML DSA 相比,提高能源效率约 2-3 倍,并且
在典型的本地数据中心1中,与这些 DSA 相比,CO2e 减少了约 20 倍。
因此,TPU v4 的性能、可扩展性、效率和可用性使其成为大型语言模型的理想工具。
TPU v4 提供百亿亿级 ML 性能,4096 个芯片由内部开发的行业领先的光电路开关 (OCS) 互连。您可以在下方看到八分之一的 TPU v4 pod。谷歌的 Cloud TPU v4 在每个芯片的基础上平均比 TPU v3 高出 2.1 倍,性能功耗比提高了 2.7 倍。TPU v4 芯片的平均功率通常仅为 200W。
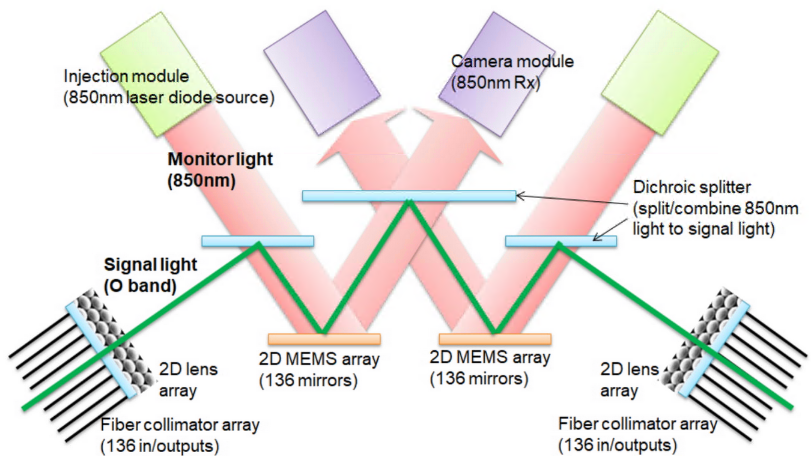
TPU v4 是第一台部署可重构 OCS 的超级计算机。OCS 动态重新配置其互连拓扑,以提高规模、可用性、利用率、模块化、部署、安全性、功率和性能。与 Infiniband 相比,OCS 和底层光学组件更便宜、功耗更低且速度更快,不到 TPU v4 系统成本的 5% 和系统功耗的 5% 以下。下图显示了 OCS 如何使用两个 MEM 阵列工作。不需要光到电到光的转换或耗电的网络分组交换机,从而节省了电力。
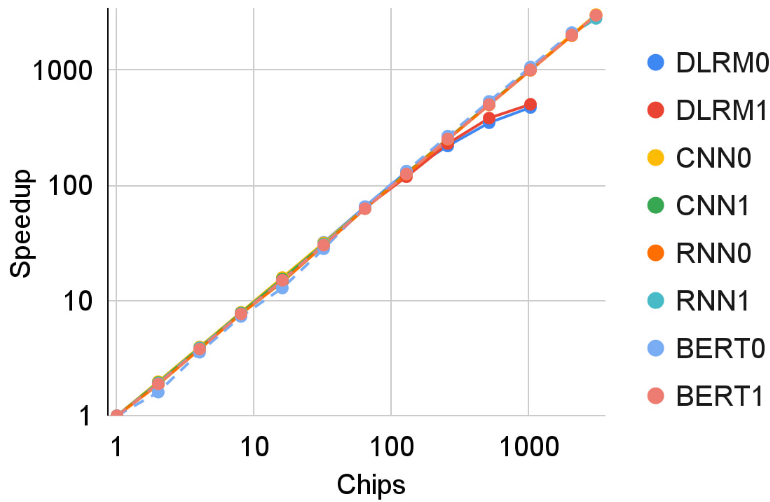
强大而高效的处理器与分布式共享内存系统的结合为深度神经网络模型提供了卓越的可扩展性。TPU v4 生产工作负载在各种模型类型上的可扩展性如下图所示。
动态 OCS 可重新配置性也有助于提高可用性。电路切换使得绕过故障组件变得容易,因此像 ML 训练这样的长时间运行的任务可以一次使用数千个处理器数周。这种灵活性甚至允许我们更改超级计算机互连的拓扑结构以加速 ML 模型的性能。
性能、可扩展性和可用性使 TPU 超级计算机成为 LaMDA、MUM 和PaLM等大型语言模型的主力。在 TPU v4 超级计算机上训练时,540B 参数的 PaLM 模型在超过 50 天的时间里保持了 57.8% 的峰值硬件浮点性能。TPU v4 的可扩展互连还解锁了多维模型分区技术,可以为这些 LM实现低延迟、高吞吐量推理。
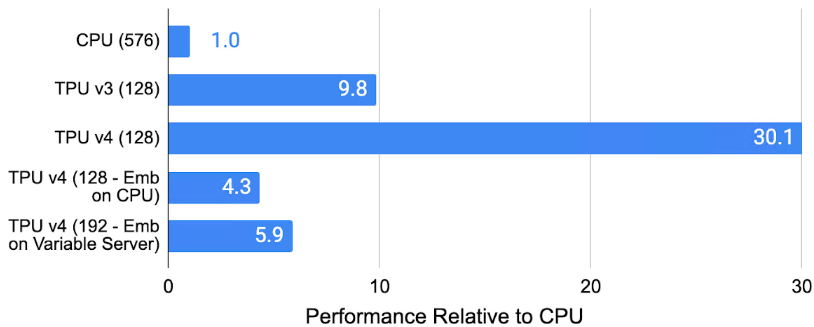
TPU 超级计算机也是第一台支持嵌入的硬件,嵌入是用于广告、搜索排名、YouTube 和 Google Play 的深度学习推荐模型 (DLRM) 的关键组成部分。每个 TPU v4 都包含第三代 SparseCores 数据流处理器,可将依赖嵌入的模型加速 5-7 倍,但仅使用 5% 的芯片面积和功率。
CPU、TPU v3、TPU v4 和在 CPU 内存中嵌入的 TPU v4(不使用 SparseCore)上的内部推荐模型的性能如下所示。TPU v4 SparseCore 在推荐模型上比 TPU v3 快 3 倍,比使用 CPU 的系统快 5-30 倍。
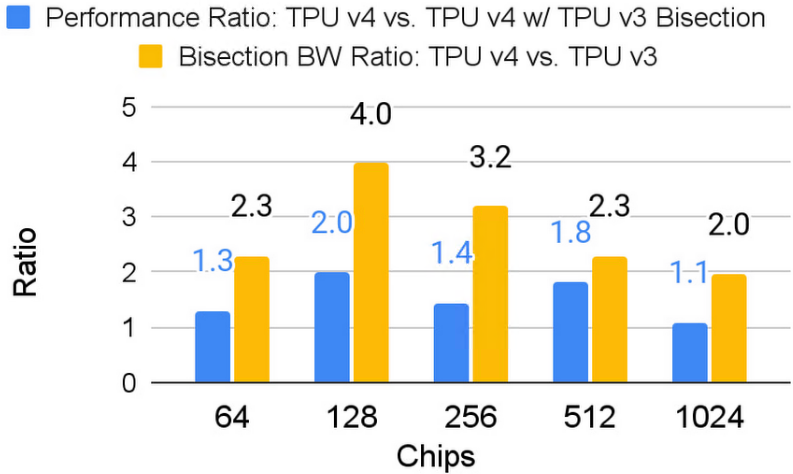
嵌入处理需要大量的全对多通信,因为嵌入分布在 TPU 芯片周围,在模型上协同工作。这种模式强调共享内存互连的带宽。这就是 TPU v4 使用 3D 环面互连的原因(相对于使用 2D 环面的 TPU v2 和 v3)。TPU v4 的 3D torus 提供更高的二等分带宽——即从一半芯片到另一半的带宽穿过互连的中间——以帮助支持更多的芯片和更高的 SparseCore v3 性能。下图显示了 3D 环面带来的显着带宽和性能提升。
TPU v4 自 2020 年以来一直在谷歌运行,并于去年在谷歌云上为客户提供。自推出以来,TPU v4 超级计算机已被全球领先的 AI 团队积极使用,用于跨语言模型、推荐系统和生成 AI 的前沿 ML 研究和生产工作负载。例如,Allen Institute for AI是一家由 Paul Allen 创立的非营利性机构,其使命是为公共利益开展具有高影响力的 AI 研究,它从 TPU v4 架构中受益匪浅,并且能够解锁他们的许多大规模,高影响力的研究计划。
“最近,许多研究人员转向云 TPU,因为它们能够轻松地跨多个处理单元进行分布。使用 GPU,一旦你扩展到单台机器之外,你就需要调整你的代码以进行分发,你可能会对服务器之间的连接速度感到失望,”艾伦人工智能研究所高级工程总监迈克尔施密茨说。“但是使用云 TPU,你可以将单个工作负载无缝扩展到数千个芯片,所有芯片都通过高速网状网络直接相互连接。”
Midjourney是领先的文本到图像 AI 初创公司之一,一直在使用 Cloud TPU v4 来训练他们最先进的模型,巧合的是它也被称为“第四版”。
Midjourney 创始人兼首席执行官 David Holz 表示:“我们很自豪能与 Google Cloud 合作,为我们的创意社区提供无缝体验,该体验由 Google 全球可扩展的基础设施提供支持。”带有 JAX 的 TPU,到在 GPU 上运行推理,TPU v4 允许我们的用户将他们充满活力的想法变为现实的速度给我们留下了深刻的印象。”
我们很自豪地在国际计算机体系结构研讨会上发表的一篇论文中分享我们 TPU v4 研究的更多细节,我们期待与社区讨论我们的发现。