Dataplex 是一种智能数据结构,可帮助您统一分布式数据并跨数据自动化数据管理和治理,以支持大规模分析。
此外,您可以使用 Dataplex 中的目录功能发现和管理各种孤岛中的元数据。请参阅数据目录概述。对于存储在 Cloud Storage 和 BigQuery 中的数据,Dataplex 使您能够:
跨存储在多个 Google Cloud 项目中的数据构建特定于域的数据网格,无需任何数据移动。
使用一组权限一致地管理和监控数据。自动发现元数据,并使数据可以安全地访问并可通过 BigQuery 作为外部表和开源应用程序(例如 SparkSQL、Presto 和 HiveQL)进行查询。
运行数据质量和数据生命周期管理任务,包括无服务器 Spark 任务。
使用完全托管的无服务器 Spark 环境探索数据,只需轻松访问笔记本和 SparkSQL 查询。
为什么使用 Dataplex?
企业的数据分布在数据湖、数据仓库和数据集市中。Dataplex 使您能够在不移动任何数据的情况下发现、管理和统一这些数据,根据您的业务需求组织它,并集中管理、监控和治理这些数据。Dataplex 支持跨分布式数据的元数据、安全策略、治理、分类和数据生命周期管理的标准化和统一。
Dataplex 的工作原理
Dataplex 以不需要数据移动或复制的方式管理数据。当您识别新的数据源时,Dataplex 会收集结构化和非结构化数据的元数据,使用内置的数据质量检查来增强完整性。
Dataplex 自动将所有元数据注册到一个统一的 Metastore 中。您还可以通过各种 Google Cloud 服务(例如 BigQuery、Dataproc Metastore、数据目录)和开源工具(例如 Apache Spark 和 Presto)访问数据和元数据。
术语
Dataplex 通过使用以下结构抽象出底层数据存储系统:
Lake:代表数据域或业务单元的逻辑结构。例如,要根据组使用情况组织数据,您可以为每个部门(例如,零售、销售、财务)设置一个湖。
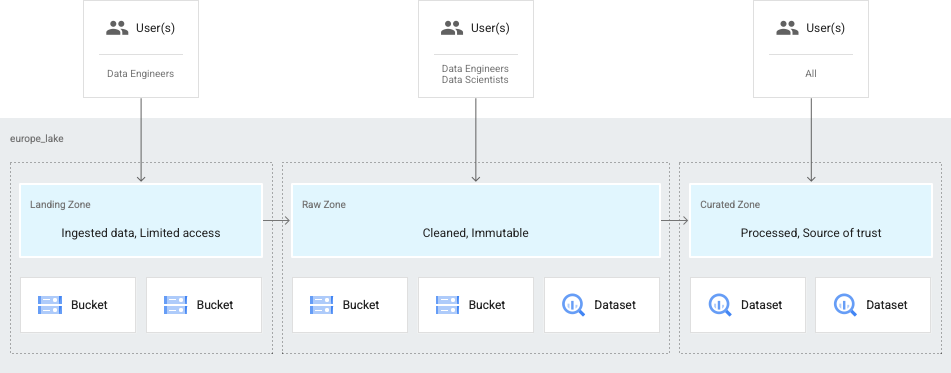
Zone:湖中的子域,可用于按阶段(例如 , landing, raw, ) curated_data_analytics、curated_data_science用途(例如数据合同)或限制(例如安全控制、用户访问级别)对数据进行分类。区域有两种类型,原始的和策划的。
原始区域:原始格式的数据,不受严格的类型检查。
Curated zone:经过清理、格式化并准备好进行分析的数据。数据是柱状的,Hive 分区的,在 Parquet、Avro、Orc 文件或 BigQuery 表中。数据经过类型检查,例如,禁止使用 CSV 文件,因为它们不适合 SQL 访问。
资产:资产映射到存储在 Cloud Storage 或 BigQuery 中的数据。您可以将存储在单独的 Google Cloud 项目中的数据作为资产映射到单个区域中。
实体:实体表示结构化和半结构化数据(表)和非结构化数据(文件集)的元数据。
常见用例
本节概述了使用 Dataplex 的最常见用例。
以域为中心的数据网格
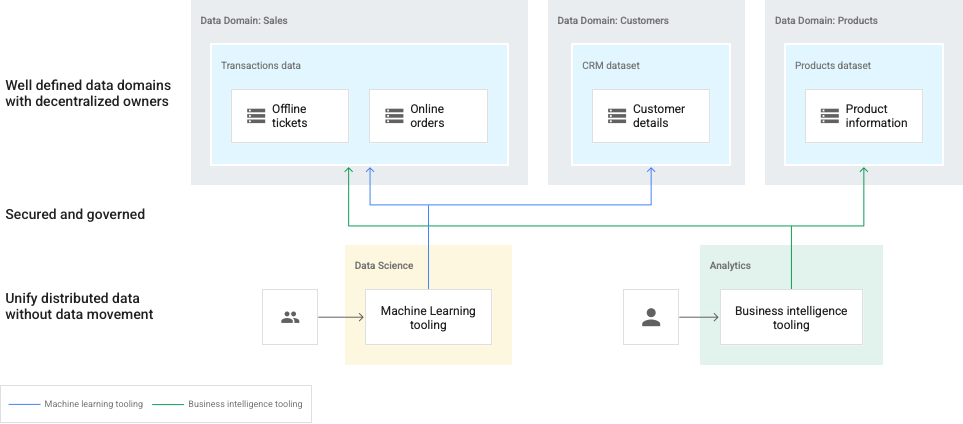
使用这种类型的数据网格,数据被组织到企业内的多个域中,例如,销售、客户和产品。数据的所有权可以去中心化。用户可以订阅来自不同域的数据。例如,数据科学家和数据分析师可以从不同的领域汲取经验,以实现机器学习和商业智能等业务目标。
在下图中,域由 Dataplex 湖表示,并由不同的数据生产者拥有。数据生产者在其领域拥有创建、管理和访问控制权。然后,数据消费者可以请求访问湖泊(域)或区域(子域)以进行分析。
在这种情况下,数据管理员需要保留整个数据格局的整体视图。
Dataplex:多个数据域的网格。
域:销售、客户和产品数据湖。
域中的区域:用于单个团队或提供托管数据合同。
资产:存储在 Cloud Storage 存储桶或 BigQuery 数据集中的数据,可以存在于与 Dataplex 网格不同的 Google Cloud 项目中。
您可以通过将区域内的数据分解为原始层和精选层来扩展此场景。通过为域和原始或精选数据的每个排列创建区域来执行此操作:
原始销售
销售策划
客户原始
客户策划
产品原料
精选产品
基于准备的数据分层
另一个常见的用例是,您的数据仅供数据工程师访问,随后经过改进并提供给数据科学家和分析师使用。在这种情况下,您可以设置一个湖,为工程师可以访问的数据提供一个原始区域,为数据科学家和分析师提供的数据提供一个精选区域。