Apache Druid是一个高性能的实时数据存储,其最新版本 25.0 提供了许多改进和增强功能。主要的新特性是: 用于基于 SQL 的摄取的多阶段查询 (MSQ) 任务引擎现已准备就绪;Kubernetes 可用于启动和管理任务,无需中间管理人员;简化部署;以及 Hadoop 3.x 用户的新专用二进制文件。
为了生成实时分析并缩短洞察各种用例的时间,Druid 的设计融合了数据仓库、时间序列数据库和搜索系统的概念。
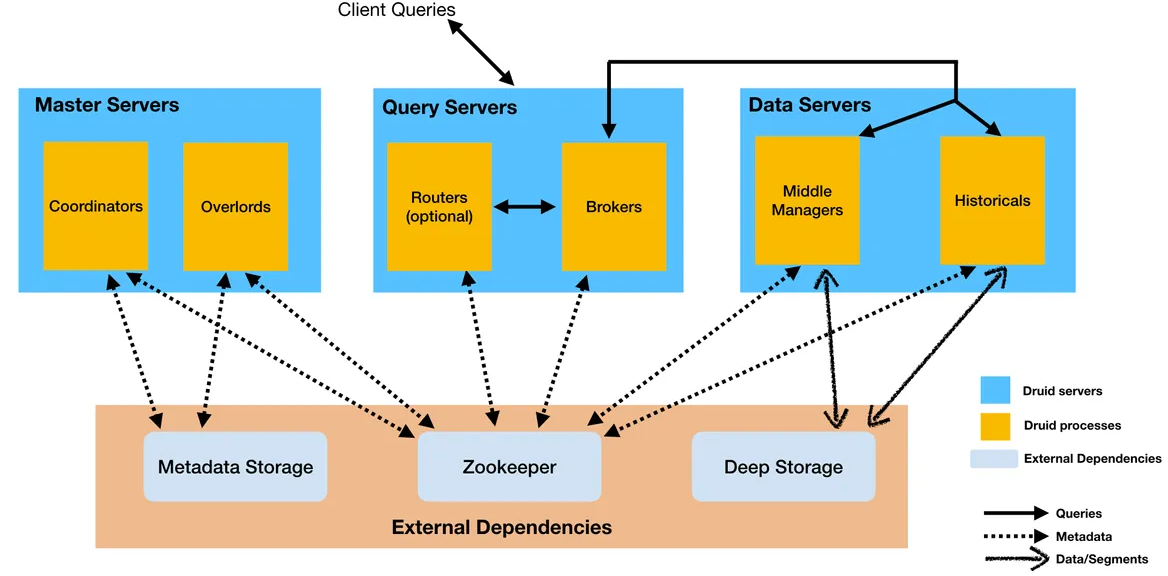
它有一个基于微服务的分布式架构,设计为云就绪,包括多种类型的服务,例如:管理集群上数据可用性的协调器服务,控制数据摄取工作负载分配的霸王服务,处理来自外部客户端和摄取数据的MiddleManager 服务的查询。
下图展示了 Apache Druid 的架构:
在摄取阶段,Druid 从源系统读取数据并将其存储在称为段的数据文件中。通常,每个段文件包含几百万行。每个段文件都按时间分区,并组织成单独存储的柱状结构,以通过仅扫描查询实际需要的那些列来减少查询延迟。
Druid 支持流式和批量摄取。它连接到原始数据源,通常是消息总线,例如Apache Kafka(用于流式数据加载),或分布式文件系统,例如HDFS或基于云的存储,例如Amazon S3和Azure Blob Storage(用于批量数据加载) ),并且可以在称为“索引”的过程中将原始数据转换为更加读取优化的格式(段)Apache Druid 可以摄取 JSON、CSV、Parque t、Avro和其他自定义格式的非规范化数据。
可以使用Druid SQL查询 Druid 数据源中的数据。Druid 将 SQL 查询翻译成它的原生查询语言。
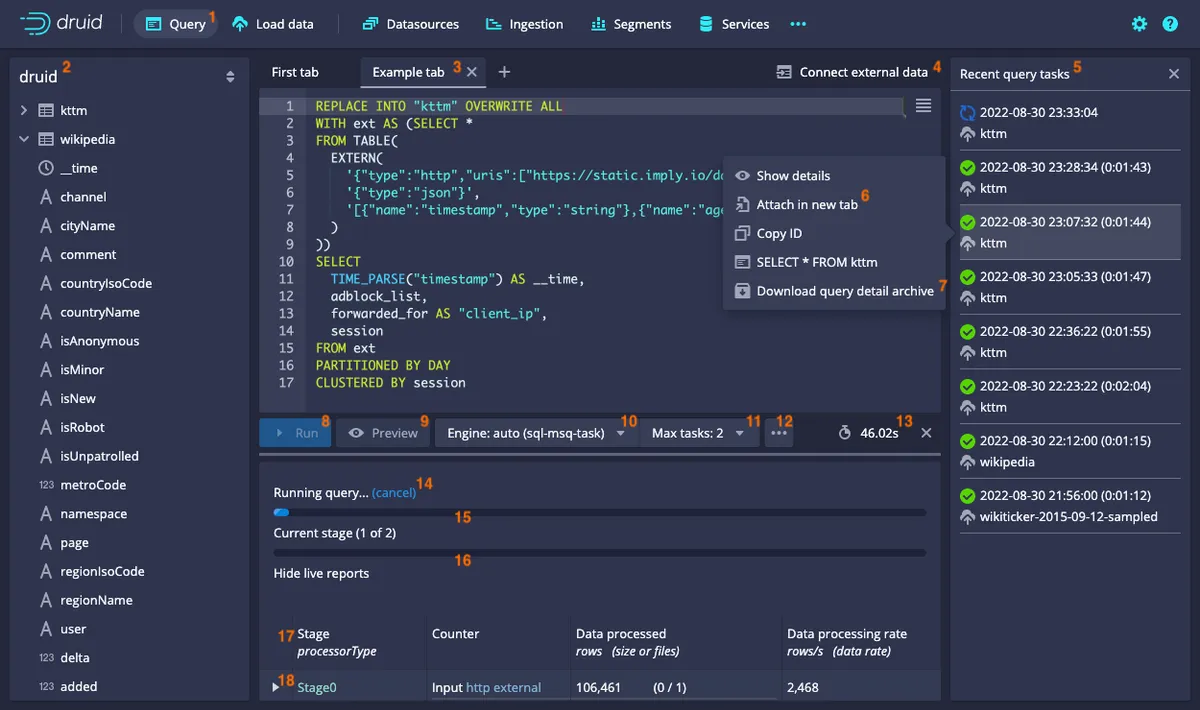
Druid 带有一个 Web 控制台,可用于加载数据、管理数据源和任务以及控制服务器状态和段信息。此外,您可以在控制台中执行 SQL 和本机 Druid 查询。
下图显示了 Druid 的 Web 控制台:
对于实时摄取、快速查询性能和高正常运行时间至关重要的情况,经常使用 Apache Druid。
因此,Druid 通常用作需要快速聚合或为分析应用程序的 GUI 提供支持的高度并发 API 的后端。Druid 最适合处理面向事件的数据。
典型的应用领域是:点击流分析(网络和移动分析)、风险/欺诈分析、网络遥测分析(网络性能监控)、应用程序性能指标和商业智能/OLAP。
它被许多大公司使用,如Airbnb、英国电信、思科、eBay、Expedia、Netflix和Paypal ,并且在Github上拥有超过 12k 颗星。关于作者,Andrea 是 DXC Technology 的一名软件架构师。此前他曾在惠普工作。Andrea 目前专注于 Java、云原生应用程序和微服务。他对与计算机