捕获数据库资源利用率有助于您了解工作负载特征和数据库使用趋势。此数据充当基线,可以将其与以后的测量结果进行比较,以识别和调查性能问题。偏差可以指示需要性能调整、数据库维护或配置更改的关注区域。
资源利用率通常会捕获影响数据库性能的指标,例如操作系统和数据库使用情况、数据库等待事件和查询处理时间。在正常业务操作期间定期收集此数据可以深入了解数据库实例的运行状况。
Amazon Relational Database Service ( Amazon RDS)每隔 1 分钟自动将指标数据发送到Amazon CloudWatch 。周期为1 分钟的数据点可使用 15 天。这意味着您拥有有关实例的历史信息,可以作为起点。您可以使用收集的指标在较高级别了解驱动数据库实例资源利用率的应用程序的工作负载模式,例如 CPU、内存、磁盘、网络和客户端连接。
Amazon RDS 提供以下监控工具来帮助您了解 RDS 实例的资源利用率:
Amazon RDS 高级监控
Amazon RDS 性能洞察
在此博客中,我们将演示如何在Amazon RDS for SQL Server中捕获和调整资源利用率指标。
Amazon RDS增强监控
增强监控为运行数据库实例的操作系统提供实时指标。这些指标可以配置到 1 秒的粒度,并且可以通过 Amazon RDS 控制台或 API 访问。高级监控通过数据库实例上的代理收集指标,而 CloudWatch 在管理程序层收集指标。有关详细信息,请单击以下有关增强监控的链接。
您可能想知道应该捕获性能指标多长时间。理想情况下,您应该在高峰业务时间、正常操作和周期性事件(例如每月作业处理)等重要周期内捕获足够的信息。默认情况下,高级监控指标在 CloudWatch Logs 中存储 30 天,但您可以延长此期限。
以下是一些重要指标:
CPU 利用率——监控 CPU 利用率有助于确定性能问题是否由 CPU压力引起。例如,如果您发现出现性能问题时 CPU 利用率为 80%,而上周同一时间 CPU 利用率相似且没有报告任何问题,则很可能是 CPU 不是脖子。
磁盘——您可以使用读写 IOPS 等指标来跟踪 I/O 和存储使用模式,以确定趋势。它还可以帮助规划存储容量以在可用卷类型(例如gp2 /gp3 和io1 /io2 磁盘)之间进行选择。
内存——一些性能问题可能与内存瓶颈有关。借助 Advanced Monitoring,您可以跟踪系统内存使用情况和模式(总内存和可用内存)和 SQL Server 内存(总 SQL Server 内存)以识别瓶颈。
网络— Advanced Monitoring 收集的网络性能指标(KB/秒网络读取和 KB/秒网络写入)对于跟踪通过网络传输的数据量非常有用。
通过这些指标,您可以很好地了解业务流程的关键日期和时间段内的资源利用率。这些值可以提供资源利用率的整体视图,这在需要进行比较以识别潜在瓶颈时很有用。
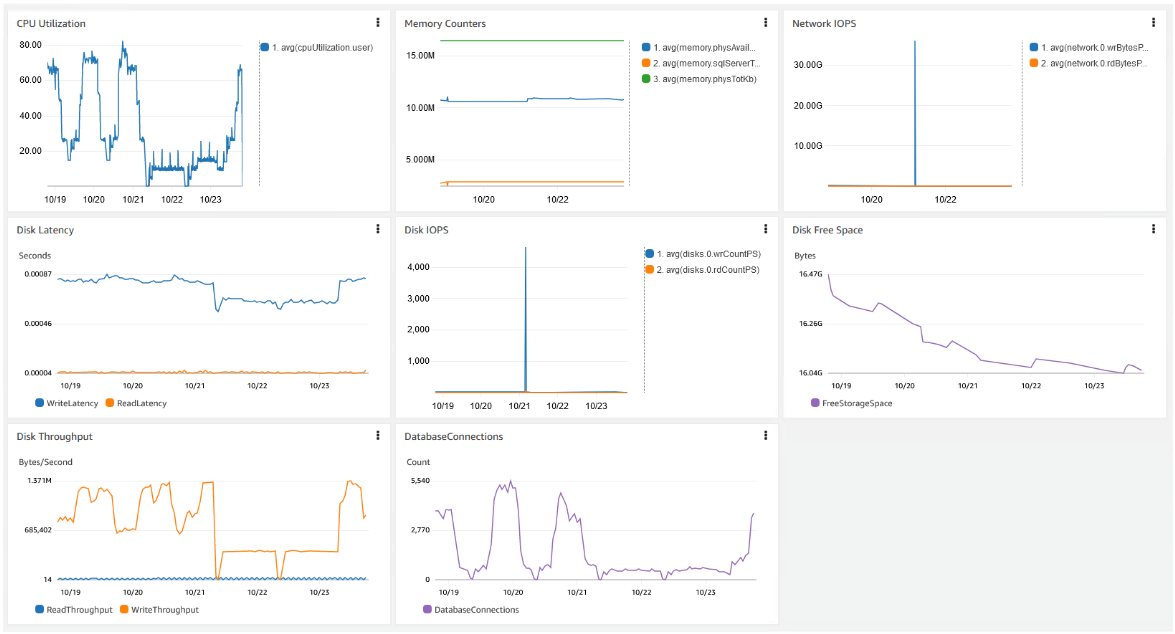
您可以在 CloudWatch 中创建一个控制面板,以集中查看此处讨论的这些性能指标。以下屏幕截图显示了包含来自 CloudWatch 和 Advanced Monitoring 的数据的综合控制面板。
Amazon RDS 性能洞察
Performance Insights 是一种监控工具,可提供有关 RDS 数据库性能的信息。Performance Insights 免费套餐每秒从 RDS 数据库收集数据,可以保留 7 天。对于长期性能趋势,您可以将历史连续性能数据延长至两年。对于每个 RDS 数据库引擎,Performance Insights 根据引擎的本机性能指标显示略有不同的信息。借助 Performance Insights,您可以收集负载趋势一段时间内数据库的(加载)、主要等待类型和主要 SQL 查询。您可以使用此信息与当前数据进行比较,以找出可能的根本原因。
大多数 SQL Server DBA 都熟悉用于诊断和调试 SQL Server 问题的动态管理视图 (DMV)。使用 DMV,数据按原样收集,您需要开发机制来了解使用趋势。这就是 Performance Insights 通过自动化数据收集和保留来提供帮助的地方。
以下是一些重要指标:
访问方法 - 页面拆分- 这可能会导致 I/O (I/O) 瓶颈,高数字可能表明需要进行维护活动,例如重建索引并可能重新访问服务器配置。填充因子。
锁和锁——锁的争用会导致 SQL Server 出现性能问题,跟踪此信息很重要,不仅可以进行趋势分析,还可以发现需要调整的 SQL 以便数据库更好地执行。您可以跟踪阻塞的进程和死锁数。
内存管理器——未决内存租约可以帮助您跟踪一段时间内的内存瓶颈。
SQL 统计数据——Performance Insights 中提供了多种 SQL 统计数据,可帮助您了解有助于正常数据库加载的任务,例如批处理请求、SQL 编译和 SQL 重新编译。
缓冲区管理器——页面预期寿命和缓冲区高速缓存命中率可以帮助您检测内存压力。页面读取与页面写入可以提供优化路径的指导,例如,如果需要彻底检查索引。
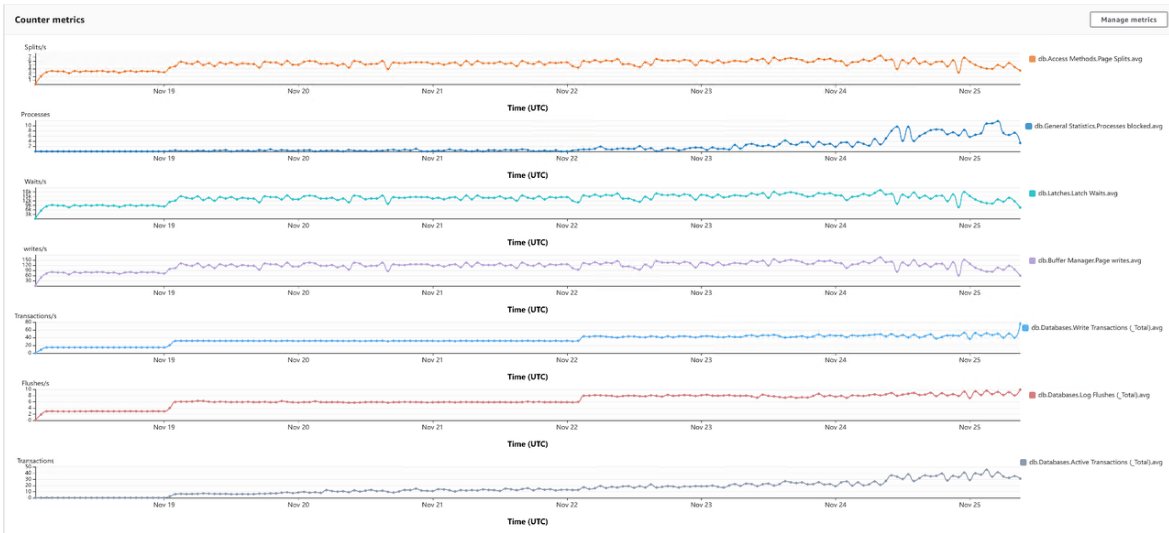
这些指标提供有关 SQL Server 性能的信息。您可以深入了解操作系统和数据库指标,包括性能指标,以了解问题的根本原因。以下屏幕截图显示了这些指标的示例。
DMV 和查询存储
识别异常后,您可以使用 DMV 深入研究和调试性能问题。有关详细信息,请参阅动态系统管理视图。
从 SQL Server 2016 开始,Amazon RDS for SQL Server 还支持查询存储,您可以使用它来跟踪和管理 SQL 语句的查询计划。有关更多信息,请参阅Amazon RDS for SQL Server 现在支持 Microsoft SQL Server 2016。
诊断和调试问题:CPU 利用率
让我们来看一个常见的场景,应用程序在昨天之前运行良好,而现在却出现性能下降。在此用例中,您通过 CloudWatch 警报或用户投诉了解到这一点。
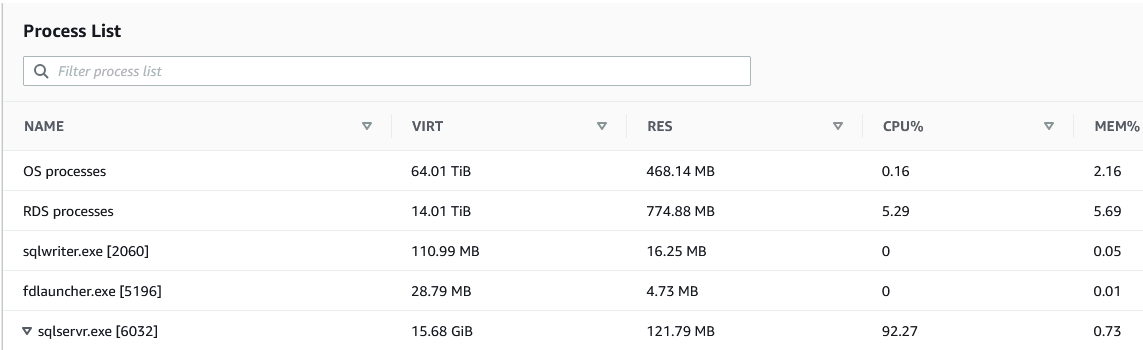
您开始通过调查指标来诊断问题。使用 CloudWatch,您可以看到 CPU 利用率指标很高,可能超过 90%。您想知道 SQL Server 进程是否导致了高百分比。您可以通过Process List下Monitoring选项卡下的 Amazon RDS 控制台执行此操作。
这是跟踪 RDS 实例的资源利用率可以提供帮助的地方。使用捕获的数据,可以有效地识别 CPU 使用率随时间的变化趋势。借助 Advanced Monitoring,您可以了解过去 30 天实例的 CPU 使用率趋势,这可以表明这是否正常。
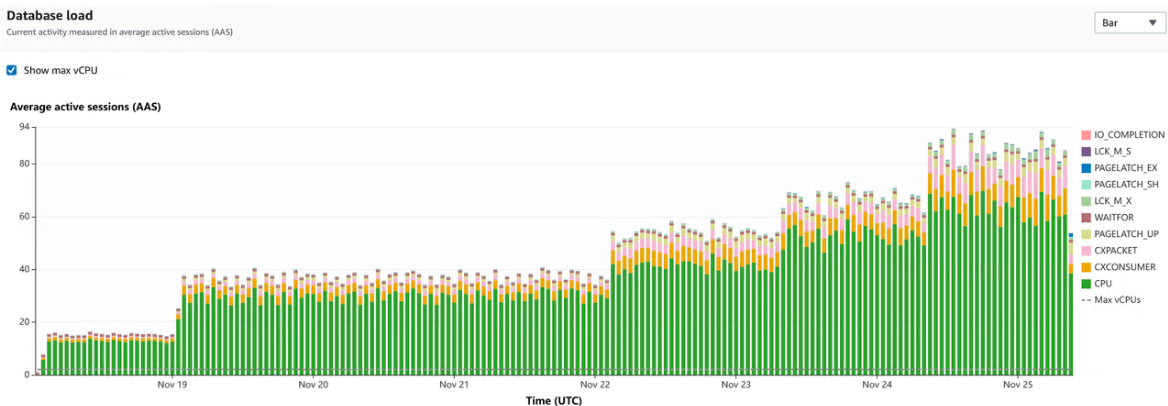
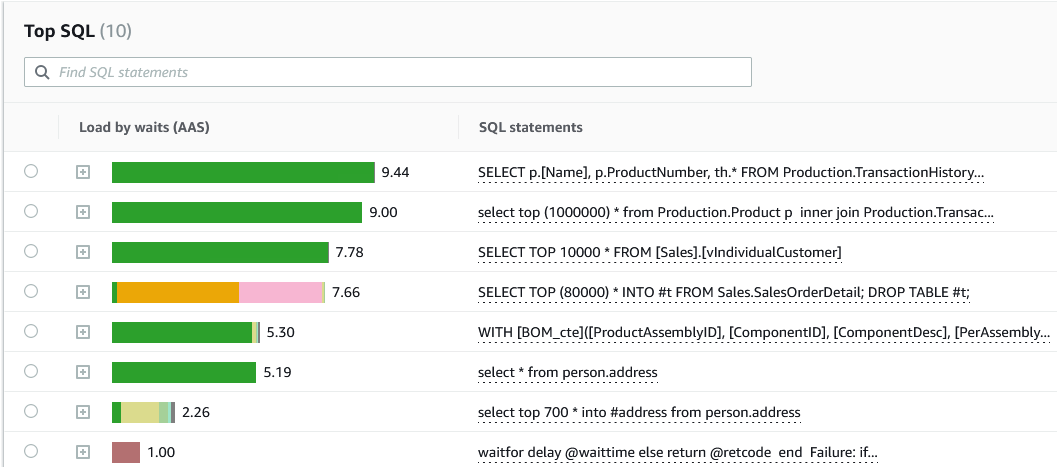
下一步是使用 Performance Insights 中捕获的数据来识别导致 CPU 负载的查询。以下屏幕截图显示了随时间累积的数据的图表。
基于此图,我们可以看到 CPU 是实例中最大的等待类型,并且它在一段时间内有所增长。该趋势还为容量规划提供了必要的数据。
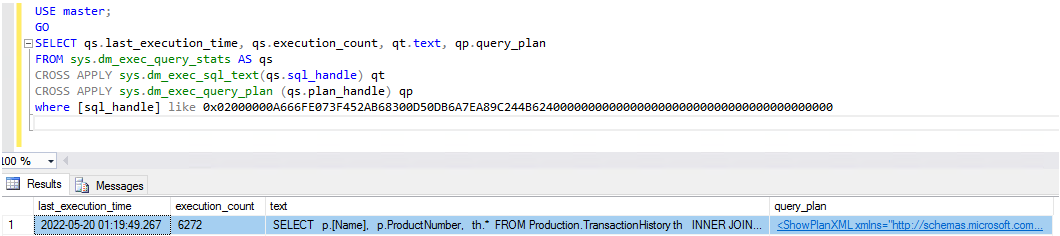
您可以向下钻取到特定日期或时间,以查看按 CPU 使用率排序的热门 T-SQL 查询列表。您可以通过 DMV 获取执行计划和有关查询的更多详细信息。
在此示例中,我们能够确定导致高 CPU 负载的前三个查询。除了查询本身,您还可以识别运行这些查询的排名靠前的主机和排名靠前的用户,这使得故障排除过程更加容易。
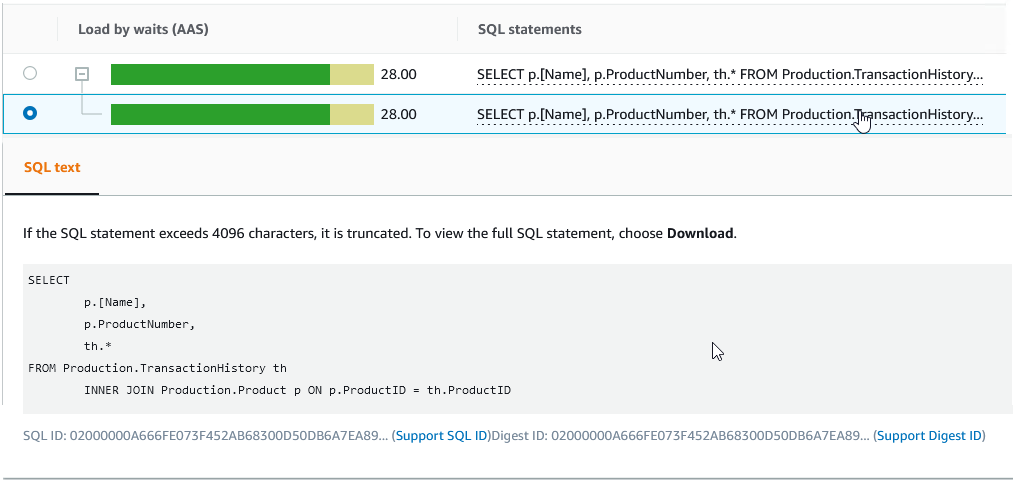
让我们以第一个查询为例。要通过SQL Server Management Studio (SSMS) 获取查询执行统计信息和查询执行计划,首先需要查询的一些信息,这些信息可以通过Performance Insights 获取。
SQL ID 是您为 DMV 提供的值,用于获取统计信息和执行计划。您需要在 SQL ID 前加上 0x 前缀,如以下屏幕截图所示。
获得查询计划后,下一步就是使用已知的查询优化方法优化查询。
结论
在本文中,我们了解了 Amazon RDS for SQL Server 的增强监控和性能洞察,它们提供了一种捕获和分析实例运行状况和使用模式的好方法。掌握此信息有助于您优化性能和排除性能故障。您可以使用本文中的方法来帮助您提高实例性能。作者:Barry Ooi,专门研究 AWS 数据库的高级解决方案架构师,和 AWS 的高级 Microsoft 解决方案架构师 Rita Ladda