我很高兴地宣布AWS Step Functions的分布式地图可用。此流程扩展了对编排大规模并行工作负载的支持,例如半结构化数据的按需处理。
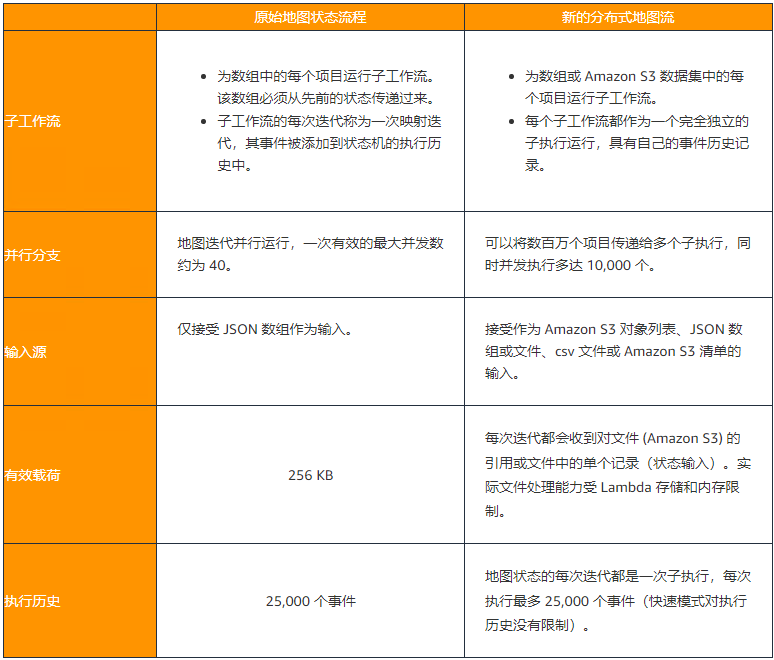
Step Function 的映射状态对数据集中的多个条目执行相同的处理步骤。现有地图状态一次只能进行 40 次并行迭代。这个限制使得扩展数据处理工作负载以并行处理数千个项目(甚至更多)变得具有挑战性。为了在今天之前实现更高的并行处理,您必须对现有的地图状态组件实施复杂的解决方法。
新的分布式地图状态允许您编写 Step Functions 来协调无服务器应用程序中的大规模并行工作负载。您现在可以迭代存储在Amazon Simple Storage Service (Amazon S3)中的数百万个对象,例如日志、图像或 .csv 文件。新的分布式地图状态可以启动多达一万个并行工作流来处理数据。
您可以通过组合 Step Functions 支持的任何服务 API 来处理数据,但通常,您将调用 Lambda 函数来使用以您喜欢的编程语言编写的代码来处理数据。
Step Functions 分布式地图支持最多 10,000 次并行执行的最大并发数,远高于许多其他 AWS 服务支持的并发数。您可以使用分布式地图的最大并发特性来确保您不超过下游服务的并发数。使用其他服务时需要考虑两个因素。首先,服务为您的帐户支持的最大并发数。其次,突发率和爬升率决定了您可以多快地达到最大并发性。
让我们以 Lambda 为例。您的函数的并发性是在给定时间处理请求的实例数。Lambda的默认最大并发配额是每个 AWS 区域 1,000。您可以随时要求增加。对于最初的流量爆发,您的函数在一个区域中的累积并发可以达到500 到 3000 之间的初始水平,这因区域而异。突发并发配额适用于您在该区域中的所有函数。
使用分布式地图时,请务必验证下游服务的配额。在开发过程中限制分布式地图的最大并发数,并相应地规划服务配额的增加。
为了将新的分布式地图与原始地图状态流进行比较,我创建了这张表。
分布式地图中的子工作流与标准工作流和低延迟、短持续时间的快速工作流一起工作。
此新功能经过优化以与 S3 配合使用。我可以直接从分布式地图配置中配置存储数据的存储桶和前缀。分布式地图在 1 亿条后停止读取,并支持最大 10GB 的 JSON 或 csv 文件。
处理大文件时,要考虑下游服务能力。让我们再次以 Lambda 为例。每个输入(例如 S3 上的文件)都必须在临时存储和内存方面适合 Lambda 函数执行环境。为了更轻松地处理大型文件,适用于 Python 的 Lambda Powertools引入了一项新的流式处理功能,以最小的内存占用量来获取、转换和处理 S3 对象。这允许您的 Lambda 函数处理大于其执行环境大小的文件。要了解有关此新功能的更多信息,请查看 Lambda Powertools 文档。
让我们看看实际效果
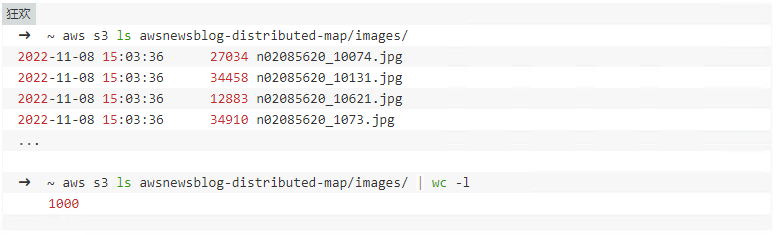
对于这个演示,我将创建一个工作流来处理存储在 S3 上的一千张狗图像。图像已经存储在 S3 上。
工作流和 S3 存储桶必须位于同一区域。
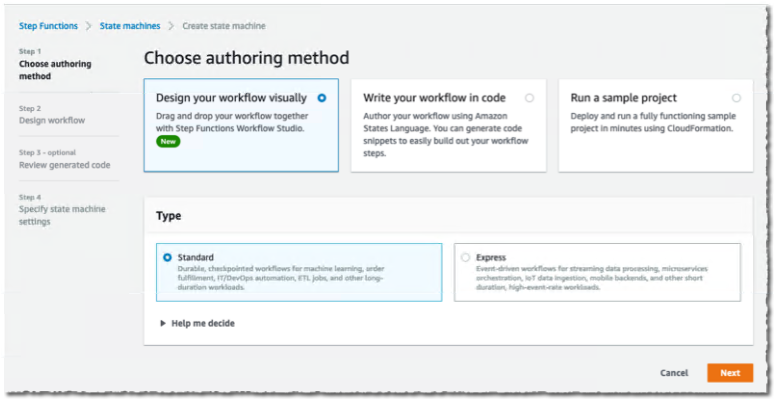
首先,我导航到AWS 管理控制台的 Step Functions 页面并选择创建状态机。在下一页上,我选择使用可视化编辑器设计我的工作流程。分布式地图适用于标准工作流程,我保持默认选择不变。我选择Next进入可视化编辑器。
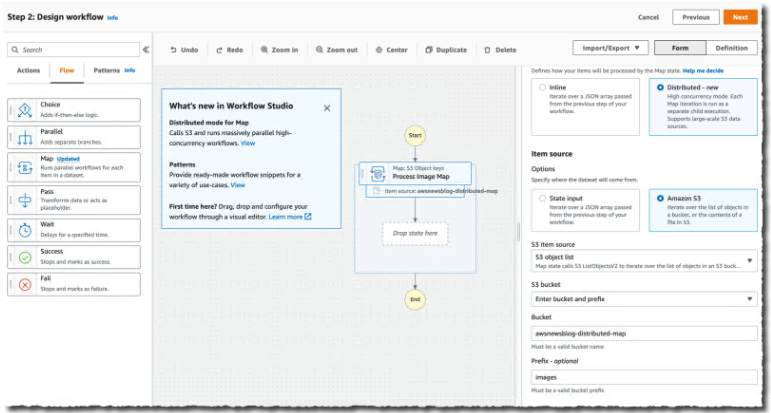
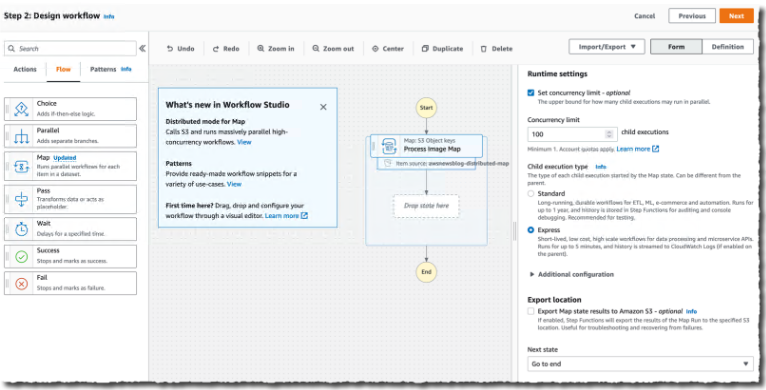
在可视化编辑器中,我在左侧窗格中搜索并选择地图组件,然后将其拖到工作流区域。在右侧,我配置组件。我选择Distributed作为Processing mode和Amazon S3作为Item Source。
分布式地图与 S3 原生集成。我输入存储桶的名称 ( ) 和存储图像awsnewsblog-distributed-map的前缀 ( )。images
在Runtime Settings部分,我选择Express for Child workflow type。我也可能决定限制并发限制。它有助于确保我们在特定账户或区域的下游服务(本演示中的 Lambda)的并发配额内运行。
默认情况下,我的子工作流的输出将聚合为状态输出,最大 256KB。要处理更大的输出,我可能会选择将地图状态结果导出到 Amazon S3。
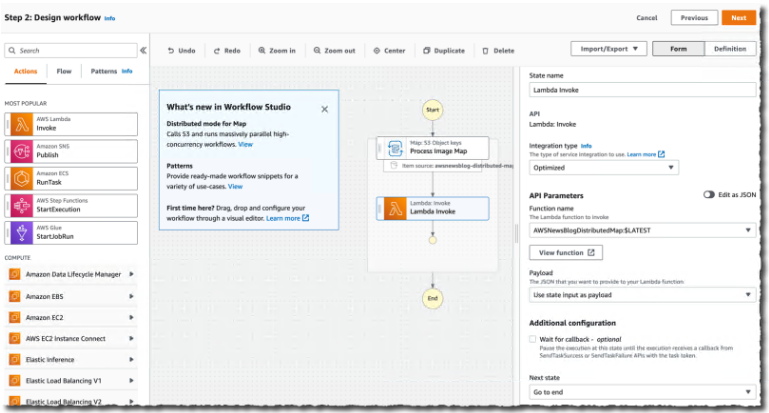
最后,我定义了对每个文件要做什么。在此演示中,我想为 S3 存储桶中的每个文件调用一个 Lambda 函数。该功能已经存在。我在左侧窗格中搜索并选择 Lambda 调用操作。我将它拖到分布式地图组件中。然后,我使用右侧的配置面板来选择要调用的实际 Lambda 函数:AWSNewsBlogDistributedMap在本例中。
完成后,我选择下一步。我在Review generated code页面(此处未显示)上再次选择Next 。
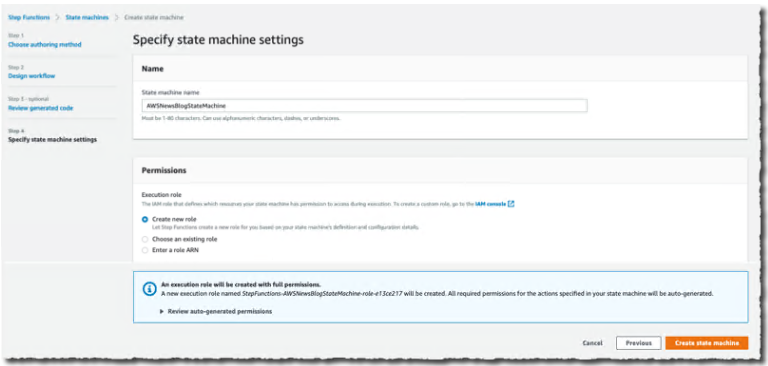
在Specify state machine settings页面上,我输入了我的状态机名称和 IAM运行权限。然后,我选择创建状态机。
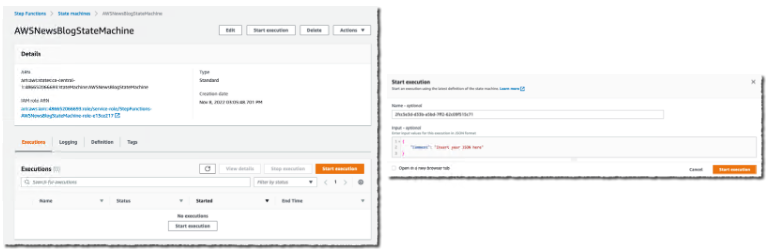
现在我准备开始执行了。在状态机页面上,我选择新工作流并选择Start execution。我可以选择输入一个 JSON 文档以传递给工作流。在此演示中,工作流不处理输入数据。我保持原样,然后选择Start execution。
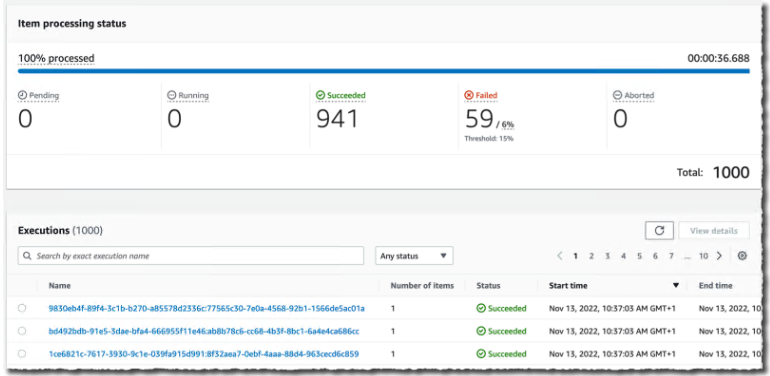
在工作流的执行过程中,我可以监控进度。我观察迭代次数,以及成功处理或错误处理的项目数。
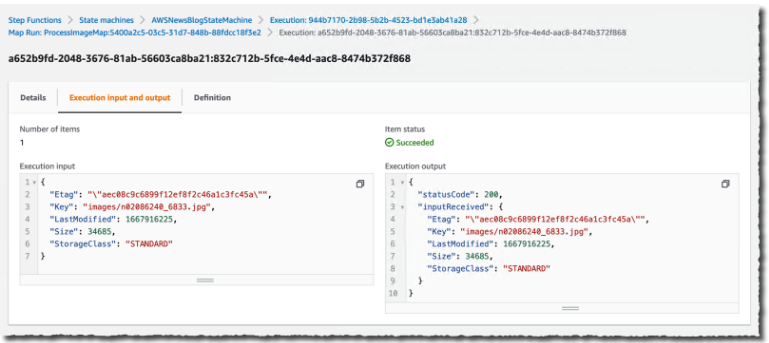
我可以向下钻取一个特定的执行以查看详细信息。
只需点击几下,我就创建了一个能够处理大量数据的大规模、高度并行的工作流。
我应该使用哪种 AWS 服务
正如在 AWS 上经常发生的那样,您可能会发现这种新功能与现有服务(例如AWS Glue、 Amazon EMR或Amazon S3 批量操作)之间存在重叠。让我们尝试区分用例。
在我的心智模型中,数据科学家和数据工程师使用 AWS Glue 和 EMR 来处理大量数据。另一方面,应用程序开发人员将使用 Step Functions 将无服务器数据处理添加到他们的应用程序中。Step Functions 能够从零开始快速扩展,这使其非常适合客户可能正在等待结果的交互式工作负载。最后,系统管理员和 IT 运营团队可能会使用Amazon S3 Batch Operations进行单步 IT 自动化操作,例如复制、标记或更改数十亿个 S3 对象的权限。撰写,塞巴斯蒂安·斯托马克,自八十年代中期第一次接触 Commodore 64 以来,Seb 一直在编写代码。他将激情、热忱、客户支持、好奇心和创造力秘密地结合在一起,激发构建者释放 AWS 云的价值。他的兴趣是软件架构、开发人员工具和移动计算。如果你想卖给他一些东西,确保它有一个 API。在推特上关注他@sebsto。